
Какой Stratum Proxy выбрать для майнинг-пула: 1:1 соединения или агрегация
Если вы строите майнинг-пул — собственный, white-label или для дата-центра — рано или поздно перед вами встанет вопрос, который на первый взгляд кажется деталью. Как прокси будет управлять соединениями между вашими майнерами и апстримом.
На практике это одно из ключевых архитектурных решений. Оно влияет на то, сколько ресурсов потребует инфраструктура при масштабировании, насколько сложной окажется диагностика, и где именно будет сосредоточена логика управления оборудованием.
В этой статье разбираем два базовых подхода — и когда какой из них оправдан.
Что такое Stratum-прокси и зачем он нужен
Прежде чем говорить об архитектуре — базовый контекст для тех, кто только начинает проектировать пул.
Stratum — это протокол, по которому ASIC-майнеры общаются с пулом. Майнер подключается к пулу, получает задание (job), считает хэши и отправляет найденные шары (shares) обратно. Пул проверяет шары, начисляет вознаграждение и периодически обновляет задания при изменении блока в сети.
Stratum-прокси появляется в этой схеме как промежуточный слой между майнерами и основным пулом. Он принимает входящие подключения от оборудования, ретранслирует задания в обе стороны и передаёт шары наверх — в апстрим-пул.
Зачем он нужен? Несколько причин:
- Региональное распределение. Если ваши майнеры физически находятся в нескольких локациях, прокси в каждом регионе снижает задержку (RTT) между оборудованием и пулом. Вместо того чтобы каждый ASIC тянулся до сервера в другой стране, он подключается к ближайшей ноде прокси.
- Буферизация и устойчивость. Прокси может кэшировать актуальное задание локально и раздавать его майнерам без обращения к апстриму при каждом запросе. Если соединение с апстримом временно прерывается — оборудование продолжает работать.
- Управление нагрузкой. Прокси — точка, где принимаются решения о маршрутизации, difficulty, балансировке соединений. Это не просто «труба» — это полноценный сервис с собственной логикой.
И вот здесь начинается архитектурный выбор.
Два подхода к организации соединений
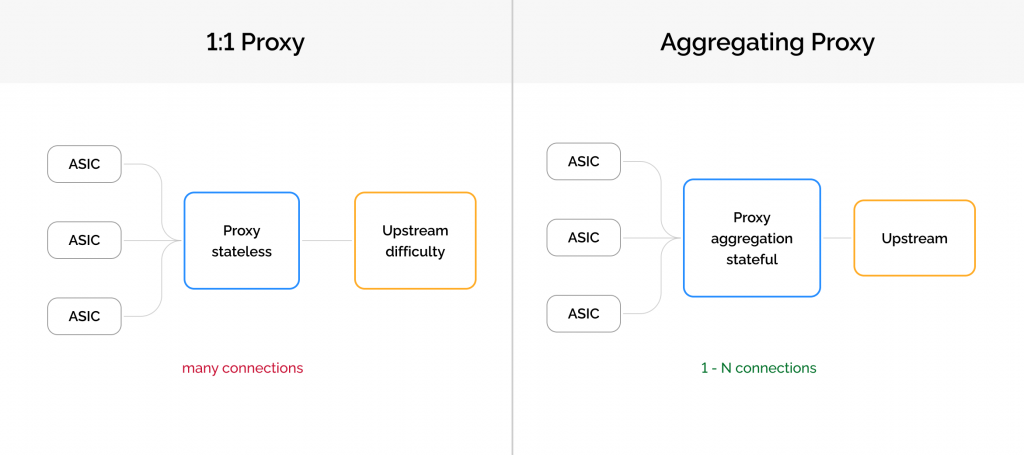
Подход 1: 1:1 прокси
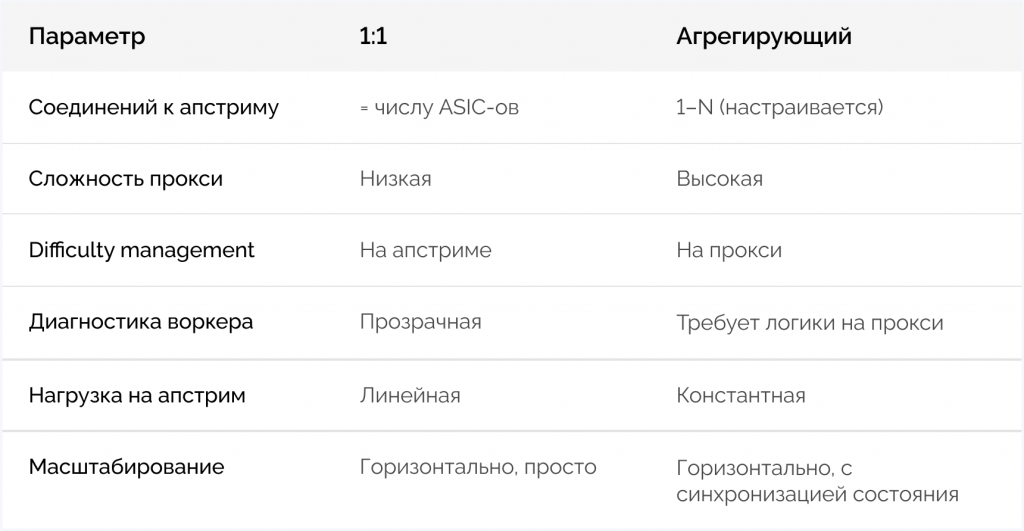
Принцип: каждый подключившийся майнер получает отдельное соединение к апстриму. 100 ASIC-ов — 100 коннектов к основному пулу.
Что это даёт:
Минимальная логика на уровне прокси. Difficulty для каждого устройства устанавливает сам апстрим — прокси не считает ничего самостоятельно. Меньше состояния, которое нужно хранить и синхронизировать.
С точки зрения диагностики — каждый воркер виден как отдельная единица. Если конкретный ASIC ведёт себя странно, это сразу заметно на уровне соединения. Биллинг и аудит выплат проще: данные по каждому устройству изолированы.
Ограничения:
Количество соединений к апстриму растёт линейно с количеством устройств. При десятках тысяч ASIC-ов это создаёт нагрузку на апстрим, которую он может ограничивать. При региональном развёртывании каждый региональный прокси «тянет» столько соединений, сколько у него устройств — что напрямую влияет на выбор и стоимость инфраструктуры.
Подход 2: Агрегирующий прокси
Принцип: множество ASIC-ов мультиплексируются в одно (или несколько) соединений к апстриму. 100 майнеров — 1 коннект наверх.
Что это даёт:
Резкое снижение нагрузки на апстрим. Для операторов, которые подключаются к чужому пулу (white-label, ретрансляция), это позволяет избежать ограничений на количество соединений с его стороны. Горизонтальное масштабирование обходится дешевле — новая нода прокси добавляет одно соединение к апстриму, а не тысячи.
Ограничения:
Прокси берёт на себя ответственность за вычисление difficulty для каждого воркера. Это не тривиально: нужно отслеживать hashrate каждого устройства, адаптировать difficulty так, чтобы share rate оставался разумным, и корректно агрегировать shares перед отправкой наверх.
Сложнее диагностика: если один воркер деградирует, это нужно детектировать на уровне прокси — апстрим видит только суммарный поток.
Больше состояния — и, соответственно, больше требований к персистентности и синхронизации между инстансами.
Когда что выбирать
1:1 — разумный выбор, если:
Вы контролируете апстрим (собственный пул) и можете управлять лимитами соединений на своей стороне.
Приоритет — прозрачность: каждый воркер виден как самостоятельная единица, упрощается troubleshooting и биллинг.
Команда хочет минимизировать собственную логику в прокси и переложить максимум на отработанные механизмы апстрима.
Агрегация — разумный выбор, если:
Вы подключаетесь к чужому апстриму с лимитами на коннекты.
Нужна мультирегиональная инфраструктура с минимальным числом исходящих соединений.
Вы готовы реализовать и поддерживать difficulty management на своей стороне — и это оправдано операционной экономией.
Гибриды и дополнительная логика
На практике граница между подходами размывается.
Агрегирующий прокси может поддерживать DevFee — механику, при которой небольшой процент хешрейта (например, 0.1%) перенаправляется на отдельный адрес. Это используется для реферальных программ, партнёрских площадок, white-label операторов. Технически это «отщипывание» части shares до агрегации — реализуется на уровне прокси и полностью прозрачно для апстрима.
Ещё один вариант — региональные прокси как кэш заданий. Прокси хранит актуальный job локально и раздаёт его подключённым ASIC-ам без обращения к апстриму при каждом запросе. Это снижает RTT для устройств в отдалённых регионах и повышает устойчивость при сетевых флапах.
Итог
Архитектура прокси — не вопрос «какой лучше». Это вопрос модели контроля: где вы хотите принимать решения, сколько состояния готовы обслуживать, и каков ваш реальный сценарий апстрима.
1:1 прозрачнее и проще в операционке. Агрегация даёт больше возможностей — но перекладывает на вас complexity, которую раньше решал апстрим.
Обе модели работают в продакшене. Выбор определяется не техническими предпочтениями, а конкретной инфраструктурной задачей.
Если вы проектируете майнинг-пул или оцениваете существующую архитектуру — готовы разобрать вашу ситуацию. Напишите нам, и мы проведём технический разбор без обязательств.
Оцени эту статью!










Оставьте свой комментарий